Your cart is currently empty!
Romancing the AI – Using Neural Networks as part of the creative process

I’m not just an artistic genius you know. I have a day job (well, not at the moment, but let’s pretend) that involves me using clever coding algorithms to tease information out of voluminous and/or complex data sets. It’s both challenging and satisfying and I’m very good at it. It’s also not so different from painting as you might think. Now, before I get into the greasy nuts-and-bolts of this, let me briefly address the DALL-Ephant in the room. Some of my art is created with the help of my pet AI. I don’t want to get into the supposed existential threat that generative AI poses to the artistic community, but I recognise that merely the mention of that TLA (two-letter acronym, and yes I went there, sue me) makes some folks a bit queasy. So let me make something clear – the AIs that I create, either as part of my day job, or to aid my creative process, are neither a threat to anyone’s livelihood, artistic or otherwise, nor the ongoing existence of humanity. I recognise the rather distressing threat that the new breed breed of AI poses to our societal cohesion, and I intend to be part of the solution rather than the problem, but neither my pet Neural Network, nor ChatGPT are sentient, or ever will be, and in my case the use of AI in no way cheapens, short-cuts, or replaces any part of my creative process, as I will discuss here at length. Nor does it steal anyone else’s creative output outside of the referencing of photos and such that is already plainly apparent in much of the rest of my artwork.
Still not convinced? Allow me to walk you through the process, so you can see for yourself. I might get a little bit technical here and there, and feel free to skim any bits that look a bit scary, none of these are essential to the understanding of the overall process. For those that can grok the nuts-and-bolts, please be nice, this was all done in my free time and doesn’t quite pass the quality control I apply to my usual day-job output!
So why do I use an AI in my creative process? Well, I vaguely remember a fit of unconstrained, impulsive ADHD enthusiasm on a long train journey a couple of years ago. I think my thought process was along the lines of “I’ve got all these images that I’ve collected from the web that I use as painting references, I wonder what would happen if applied my python skills to mess with them in interesting ways” and I set about coding my first “image mangler” using my phone right there (I was likely using Pythonista on my iPhone at that point, but were I doing this right now with my Android phone I’d use Pydroid). At that point I my idea was to algorithmically mess with pixel values to mutate the images in interesting ways. This meant dreaming up interesting algorithmic approaches that weren’t those used by the myriad image filters available as standard in all the existing image manipulation tools (e.g. the Gaussian filter).
When you’re manipulating images in any tool, such as Photoshop or GIMP or whatever, what’s actually happening in the background is that your image is converted to a 3-dimensional numerical matrix (aka an array, or sometimes vector) which represents the pixel values of that image – specifically, 3 two-dimensional arrays, one for each of the primary colours of the colour model you’re using, usually RGB – Red, Green and Blue (I could get into a long diatribe about the various colour models and how there’s really no such thing as “primary” colours, but that’s for another day). Each value in the 3 two-dimensional arrays represents a pixel intensity of the pixels that make up that image (0 meaning no colour, 255 meaning full colour). When the images are rendered the three values for each pixel are combined to produce a specific hue (in the subtractive colour model, again, for another day). If you change any of the values of any pixel, you can subtly change the resulting image once the channels are recombined. Since the digital version of this image is a simple mathematical matrix, the manipulations are usually done mathematically. So by adding or subtracting numbers from the pixel values, you can change the colour or intensity of that pixel, and those around it. Clever, eh? Most of the common filters use some pretty hefty and complicated maths, a lot of which I don’t care to spend the time trying to understand. I’m a much baser beast than is capable of such mathematical refinery, and my method is almost always “brute f***ing force” aka, arbitrarily changing shit with pretty simple numerical functions (add, subtract, divide etc.) and seeing what happens. Believe it or not, this is less clever than it sounds. And to make it even less sophisticated I reduced each image to a single channel (in effect, making it black & white, or more accuratly, monotone, since they could be rendered in any single colour) and crop them to a specific size and shape.
Now, paradoxically, it was that last step where all the real magic and fun kicked off. Yes, I produced some interesting effects by manipulating pixel values based on the values of adjacent pixels, but that was rarely the most interesting aspect of the resulting image, it was their composition.
Firstly, let me address the question of why I cropped them at all. Simply, when working with multiple mathematical vectors (one for each image), life gets a lot easier if they’re the same size. I was basically being lazy, since if I had deal with a different size and aspect ratio with every new image, I would need to write some boring code to deal with that. Bollocks to that, thought I, I’ll just make them all square.
So far so dumb. But I still had decision which square to retain from each image (presuming the image was not already square), and since I intended to run algorithm against hundreds of images, there was no way that I was going to manually choose the ideal crop for each one. So, applying my ongoing, borderline pathological, policy of brevity, I googled some code (this was back in the hazy mists of time before ChatGPT saved the world) that simply cropped the largest possible square from the centre of the image. Behold:
def crop_center(self, img, crop_width, crop_height):
img_width, img_height = img.size
return img.crop((
(img_width - crop_width) // 2,
(img_height - crop_height) // 2,
(img_width + crop_width) // 2,
(img_height + crop_height) // 2)
)Some serious shit going on there, right? If you don’t understand it, don’t worry, it’s not important. Just savour the glorious majesty of the resulting image:


I think you’ll agree with me, that that’s, at best, a pretty insensitive crop. Which is less than ideal if what you needed was for the integrity of the original image to be largely retained through the process. But I didn’t, and what I saw in this image, and many like it, was a thing of wondrous beauty. A composition so divergent it borders on blasphemy. Ejection from traditional art establishment in a 500 x 500 matrix. A compositions that I would never have thought to use, or have the balls to select, in a millions years. It was love at first sight!
So what was the actual revelation here?
- Bizarre compositions can be very pleasing
- Computers are really great at messing things up
(I’d like to point out that this latter revelation pre-dates ChatGPT and its much lauded capacity for beguiling nonsense.)
These revelations got me thinking: what other perverse ways can I coerce a computer to mess up images?
Ironically, given how easy it was to elicit this specific behaviour, figuring out new ingenious ways for serendipitous image corruption was oddly hard. Where to even start? My algorithmic approaches to date were interesting, but hardly mind-blowing. I started hunting around in the wider field of digital generative art, and found some fantastic stuff, but also some scary maths that I didn’t much feel like grappling with (although I will no doubt revisit this area at some point) and lots of largely tedious AI based approaches. However, my skulking in these dark crevices of digital creativity did resurface some arcane knowledge derived from my day job as a data scientist and analyst from a good 6 or 7 years previous when I was messing around with language models. Specifically, the working of a Neural Network type algorithm crafted at Google that was all the rage at that point called Word2Vec. Word2Vec is a direct ancestor to the modern Large Language Models such as ChatGPT. It’s what’s generically known as an autoencoder. I won’t get into the nuts and bolts of autoencoders as language models here, suffice to say that their job is to take text in at one end, and then reproduce it at some later time, as best it can. In their most basic form, then are overly complex and poorly performing compression algorithms, but in their more refined form are, well, extremely useful complex and poorly performing compression algorithms. But you’ve seen the conjuring tricks they perform via your surreptitious use of ChatGPT and no doubt use them already to churn out the sort of boring prose that you secretly used to enjoy churning out yourself. (This post was produced entirely by me and Neovim by the way, so pipe down already!).
Anyway, it took a single google search to discover that same principle can be, and has been, applied to images, and it got me pondering: I wonder what sort of weirdness an autoencoder would produce if I gave it lots and lots of images to memorise and not enough “memory” to remember them. Surely it would start to mix all the images up in fun and delightful ways?
So I immediately set about cutting and pasting bits of python code from a tutorial I found with the documentation of foundational Neural Network library Keras and a few hours later I had my results, and whoa where they results! The rest, as they say, is history. I set up a Instagram account and started to share all my delightfully warped and frequently spooky images.
For those desiring a little more specificity for what I actually did, I will elaborate a little here, but feel free to skip this bit if technical tomfoolery doesn’t float your boat.
Before I get into the tasty neural network action, a quick note on the wider technological landscape. All of the fun and wonder was created with the combination of one or more of the following elements:
- Python
- Numpy
- Keras with a Tensorflow backend fot the neural network
- The PIL image processing library
Like any Deep Learning style neural network, an autoencoder uses one or more layers of interlinked hidden layers. For my proposes, how these interlink is not particularly important, every node in each layer links to every node of the next. Where a more standard deep learning network, for example some sort of classifier, would terminate in a very narrow output layer (e.g. 1 neuron for a binary classifier), the autoencoder output layer has the same number of neurons as there is pixels in the input, namely the number of pixels in your input images. The output of that layer is scaled back up and reconstituted into an image, which is what I share. All my images are of uniform size, 500px2 initially, but higher resolution now, which, for the sake of brevity, I flatten to a 1-dimensional 250,000 wide vector, scaled from the standard 0-255 range to a unit vector for the usual reasons. The autoencoder is tasked with “minimising” the error (loss) function (I tried various, but MSE gives me the most satisfying results) of the output when compared to the original input vector. You’ll note that in the prior parentheses that I used the word “satisfying”. This was not an accident. The task here is not to produce the best, or most accurate, result, it is to produce the most artistically satisfying result, which means I specifically do not want to absolutely minimise the error function or even close, since that would result in the original images being reproduced near perfectly, which is no use at all (at least for my use-case). So instead I want to reduce the error function to the degree to which I get something that isn’t just random noise, but also isn’t a faithful representation of the image. How do I do this? I use some or all of various approaches, the point being to “constrain” the network to prevent it from doing its job properly, for example I can:
- Stop the training process prematurely when it has reduced the error function to some specific value or percentage
- Train it on far too many images for the size of the network to remember, which is almost the same as…
- Giving the network too few layers or neurons or connections to encode all the image information
- Making the central layers ridiculously small
- Use wildly divergent images (e.g. a mix up landscapes with portraits)
- Dropout layers and similar
All this while trying different hyperparameters, layer configurations and error and activation functions (ReLU tends to work the best) and combinations thereof. There is some method and theory behind my experimentations but, since there is no specific, desired output, just noodling around with stuff is just as effective.
The worst of the technical detail ends here, but I can’t promise that some won’t leak out during the rest of this overly long post, soz.
By definition, the model created by any combination of configuration is also a product of the images that are input. I deliberately don’t input all images, since I have thousands and it would take too long to train on my Mac, but it’s also not desirable to do so. The crazy randomness is in part a function of the images that are chosen and the selection of images is part of the parametrisation and vital to the creative process. By controlling how many images input, even when chosen at random, I can effect the final result – just as I control my palette and brush strokes when I paint. I have also given myself the ability to include specific images to tailor the effect of the final output. Via this method I can create collections of similar or thematically linked images.
There is a separate module whose responsibility is to grab some images and prepare them for the training, and which offers further opportunities to affect the outcome of the model by, for example, tweaking the contrast of the input images. It also allows me to experiment with different resolutions (I’ve managed to train effective models of up to 1500px2). In theory, the higher resolution the better, but the exponential growth of the input vector places some practical limits given my hardware, and varying the resolutions produces different effects, so constraining this is sometimes desirable. There’s also the issue that many of the input images are of lower resolution, which is not a problem for the model and almost certainly is responsible for some of the interesting effects created.
And as for those interesting effects? See below, they’re fascinating, aren’t they? The model mixes up and mutates the source images blending and bleeding them into one another in bizarre and unpredictable ways. Some of the source images contain text which leaks through in enticing and haunting ways. Faces peep out from the trees from which they are growing, or blend into and merge with other faces. Planets mingle with beasts and butterflies appear to emit human language. There’s a haunted unity that creates cohesion among the hideous divergence. When staring at grids of these images I feel like the demoniac substrata of the universe is malignantly whispering to me like space-warped tarot cards. This is the esoteric language of Lovecraft’s Old Gods writ in digital form (more on this later).
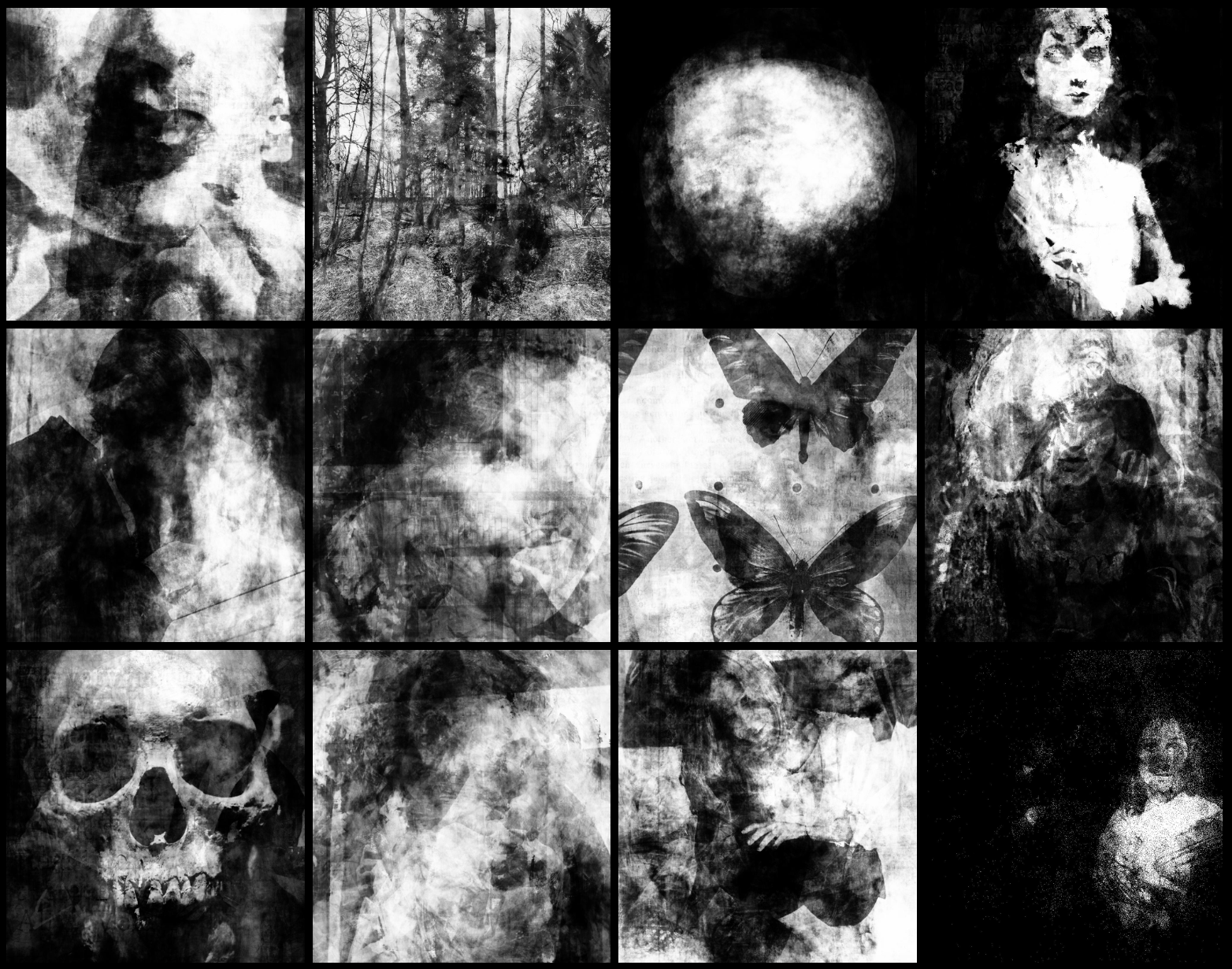
Because there is no right answer, and because I want unique images, I don’t keep the individual models created. They’re also pretty big and I don’t want to waste the disk space on them. So in effect, every image is unique, although certain input images seem to resonate more highly with the training algorithm, and so tend to turn up more prominently every time they are included in the input. I do, however, record the input parameters of the models that produced the most interesting and impressive images and reuse these. There is a fairly narrow range of parameters and inputs that yield good results, within which I still have a inexhaustible range of combinations to play with (as well as an ever growing repository of digital imagery). Many combinations and ranges of parameters merely yield white-noise or conversely overly accurate recreations, and can be discarded.
So the model gets trained from scratch every time it runs, like starting with blank canvas (metaphor both intended and unintended). Every time is a surprise and a wonder. The number of output images is exactly the same as that input, since the job of the machine is to reproduce the input images, or at least attempt to. The best models need at least 100 input images, so there are that many outputs to sort through and select the best from. Even the most effective models produce a large number of duds, by which I mean images that are completely unusable, usually because they are white-noise, or close to it, or too faithful a recreation. These can be discarded. Among the rest, many are not particularly interesting, but at an estimate, one in ten is a gem! This ratio varies greatly across the batches. Even with some home-grown tools to aid the filtering and selection process, it’s pretty laborious, but strangely dopamine filled, so it pleases and soothes my ADHD brain. I rarely adjust or doctor the images output – they are presented as is.
I could ramble on about this for a lot longer – it’s a fascinating and weirdly compulsive process, but I’ve already gone on too long. Maybe I’ll elaborate on a few of the areas that that I’ve glossed over at some point.
So what do I do with all these images, and how does that relate to my main body of work? Well, for the latter, initially at least, nothing at all. I set up a dedicated Instagram account, an obvious choice given how, when viewed via your profile page, the images are neatly arranged in grids of squares. Over time, the whole thing evolved to a convoluted, H.P. Lovecraft inspired hauntological framework called The University of Wilmarth Faculty of Eschatology. This is an ongoing labour of love, and houses thousands of the raw outputs of the models. Where it’s going, I’m not sure, but it’ll be fun finding out!
Along the way I used the images for a more abstract inspiration to my painted works. Mostly this was by way of more adventurous compositions, and via the introduction of more random and organic elements to the physical process. The images themselves were too intricate and disordered to scale up as direct references, and my original intention was to keep the two realms of my work separate. But I loved the images so much I had a nagging desire to see them on hanging next to my other art. Also, and inspired by the obsessively square digital art of my good friend and one of my favourite contemporary artists Mark Burden, I had an urge to see my works in uniform grids in the physical world.

So I set about figuring out how to do this. I could have just had them printed on nice paper and had them framed, but that felt a little lazy, especially since the creative process is already a little bit “factory”. It’s still possible that I’ll do this, but the more natural approach, given my tendency to incorporate elements of collage into my work, was to transfer the images to canvas where I could embellish and accentuate them. My smaller pieces are simply printouts from my fairly pedestrian home inkjet printer which are affixed to canvases using acrylic medium. I then go at these with acrylic inks, spray paints and the like. For the bigger one I scale up the images across multiple sheets and after which I follow a similar process. Others are simply scaled up by hand, and result in more “traditional” paintings. Regardless of which approach I use, I find the process highly enjoyable and creatively stimulating. It’s all win.

There’s a fair amount of extra bits that happen along the way, but that’s the gist of it. Having written this up, it feels like a ridiculously long, complex and convoluted process. I was worried that others might have thought me lazy for using computers and AI as part of my creative process! And I do consider this a deeply creative endeavour. At every step of the process I must make choices that affect the outcome, and the images that I choose to collect (as inputs) and share (as outputs) is based on decisions I make that are deeply peculiar to me. Were I to hand over all the code to anyone else (and I’m not averse to tidying it all up and open sourcing it at some point), I feel absolutely certain that the outputs they create would be dramatically different from mine, just as if someone else co-opted my studio and used all my materials and used the same reference images, they would yield dramatically different results. So concerned was I for a while that this process would be considered “cheating” or somehow creatively moribund, I considered not disclosing it at all. But I’m genuinely proud to have devised a such an innovative and unique approach. Maybe the works aren’t to everyone’s taste, but the same goes for the rest of my work, and anyone else’s for that matter.
For the most part I have paused my use of this approach, purely because other creative shiny things distracted me. I fully intend to resume this creative avenue and perhaps evolve it further in the future. One potential method for expanding it is to reintroduce the colour. I suspect that the warping of the hues could yield some really interesting results, or maybe just a brown mess! On the other hand, I’m really quite attached to the sea of monochrome. We’ll see I guess. There are also a plethora of other approaches to image vectorisation and model creation (e.g. convolutions) to play around with. Not to mention the essentially infinite choices of how to use the output images. In the meantime, my pet AI rests placidly in it’s cage, I’ll give it some attention when it starts gnawing at the bars.