Your basket is currently empty!

Alex Loveless – artist, data nerd and mental health and neurodiversity advocate.
Alex is a visual artist and painter based in Central Scotland. He creates works across a variety of styles and mediums in a style that could be described as Pop Art meets Art Nouveau meets pulp cover illustration. Alex is autistic, ADHD and aphantasic and hosts a podcast on art as a therapeutic outlet for mental health. He’s also a data scientist.



From the shop

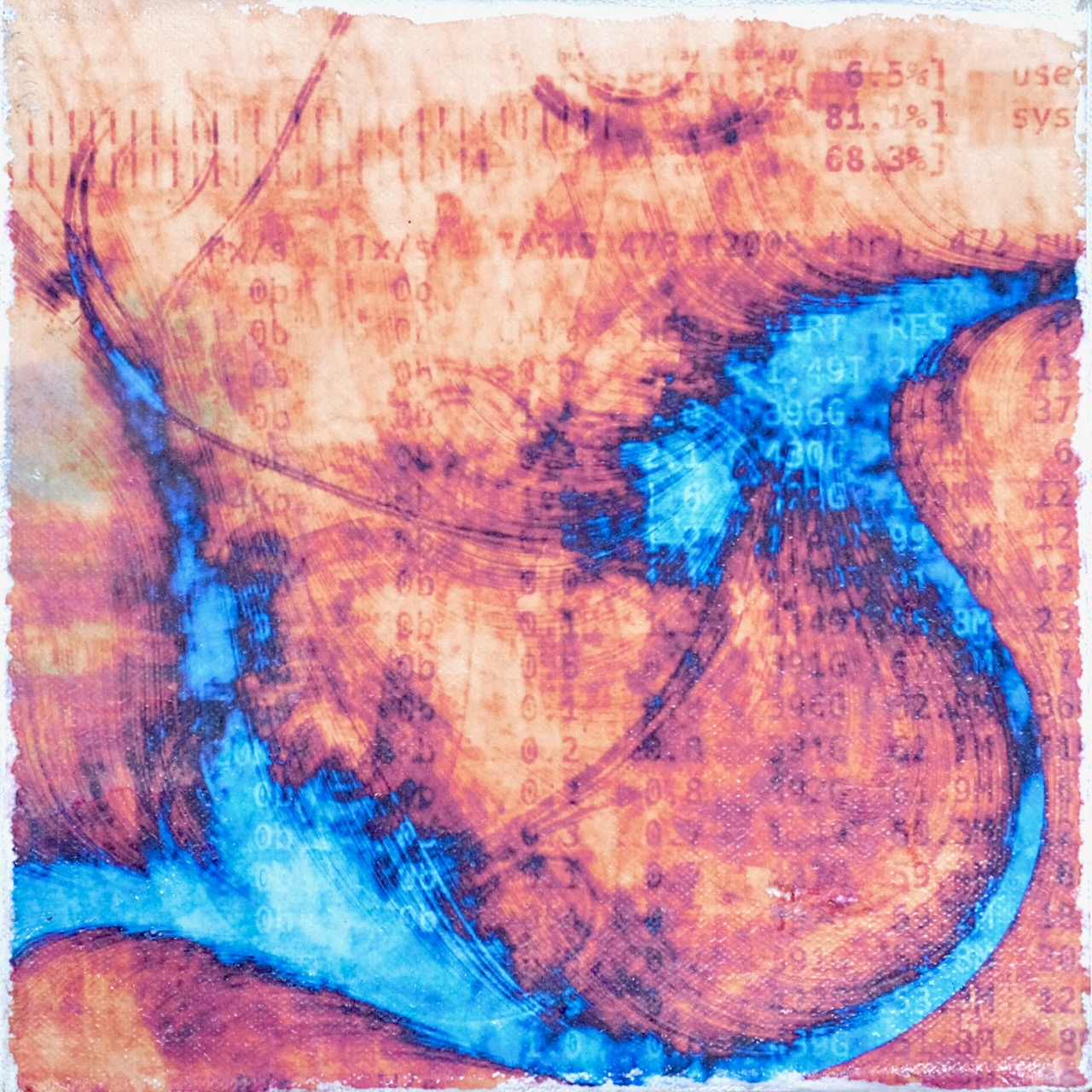
Featured Artwork – “Where Do We Go From Here?” (2019)
Has humanity reached a evolutionary dead end? Or is it just that evolution by natural selection no longer applies to the human race? This musing, abstract piece alludes to this subject.



Signature Pieces
Browse and buy some of Alex’s most celebrated and ambitious works. Across a multitude of styles, subjects and mediums, Alex creates the boldest windows into his rich world.





Listen to Alex’s podcast
talks about healing powers of creativity and provides practical tips, based on his own experience, for using the creative process for the upkeep of mental health and therapy for mental illness. Alex discusses putting the creative journey at the centre of life for artists, art lovers, the art curious, and anyone with an interest in mental health and mental illness.